Hla.jpg 查看 (2.97 KB) 金 怡泽, 2013-07-02 23:14
Hlb.jpg 查看 (3.29 KB) 金 怡泽, 2013-07-02 23:18
Hlc.jpg 查看 (1.96 KB) 金 怡泽, 2013-07-02 23:20
Hl.PNG 查看 (994 Bytes) 金 怡泽, 2013-07-02 23:36
级联分类器.jpg 查看 (22.6 KB) 金 怡泽, 2013-07-23 10:16
弱分类器训练.jpg 查看 (99.1 KB) 金 怡泽, 2013-07-31 09:04
doublethreshold.jpg 查看 (15.5 KB) 金 怡泽, 2013-07-31 09:25
双阈值.jpg 查看 (79.1 KB) 金 怡泽, 2013-07-31 09:28
231011_081021041周薇娜.pdf (3 MB) 金 怡泽, 2013-07-31 15:10


 ¶
¶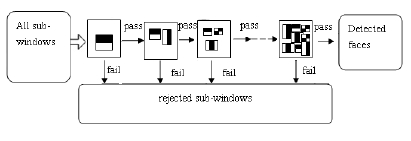 ¶
¶
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
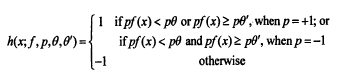{kind=link}
{kind=link}
{kind=link}
{kind=link}